SHTns is an implementation of the Spherical Harmonic Transform which aims at being accurate and fast, with direct numerical simulations in mind.
As such, the following optimizations are implemented :
Use the Fast-Fourier Transform
Any serious SHT should use the FFT, as it improves accuracy and speed. SHTns uses the FFTW library for the fast Fourier transform, a portable, flexible and blazingly fast FFT implementation.
Take advantage of mirror symmetry
This is also a classical optimization. Due to the defined symmetry of spherical harmonics with respect to a reflection about the equator, one can reduce by a factor 2 the operation count of both direct and reverse transforms.
Polar optimization
A less common, but still classic optimization : high m's spherical harmonics have their magnitude decrease exponentially when approaching the poles. SHTns use a threshold below which the SH is taken to be zero. The default value for this threshold is defined by SHT_DEFAULT_POLAR_OPT, but you can also choose it with the eps parameter of the shtns_set_grid function, trading some accuracy for more speed. Around 5% to 15% speed increase are typical values for a SHT with a large MMAX.
Cache optimizations
Cache optimizations have been carried out throughout the code. This means ordering coefficients and stripping out systematic zeros.
Spatial Size optimization
When using shtns_set_grid_auto, you can let SHTns choose the optimal spatial sizes for the spherical harmonic truncation you specified with shtns_create. The spatial sizes are chosen so that no aliasing occurs, and ensuring FFTW will perform as fast as possible.
Explicit Vectorization
Most x86 CPUs have support for Single-Instruction-Multiple-Data (SIMD) operations in double precision, allowing to perform the same double precision arithmetic operations on a vector of 2 (SSE2) or 4 (AVX) double precision numbers, effectively multiplying by 2 or 4 the computing power. Modern compilers attempt to vectorize the code, but they cannot do miracles. SHTns uses explicit vectorization extensively (thanks to the GCC vector extensions) to use the full computing power of your CPU.
Discrete Cosine Transform optimization
This is a non-trivial optimization mostly efficient on small m's, which can significantly decrease the operation count.
It can be noticed that Spherical Harmonics are polynomials of order 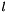 in
in  (multiplied by
(multiplied by 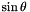 for odd m's). Thus, going to DCT space and summing there can help to further reduce the number of operations.
for odd m's). Thus, going to DCT space and summing there can help to further reduce the number of operations.
Using a DCT requires a regular grid instead of the usual Gauss grid, and this means doubling the number of grid points to keep an equally accurate quadrature (Tchebychev quadrature), reducing the performance gain from the DCT to zero, when not performing worse.
However, SHTns uses a quadrature inspired by the Fejer quadrature (or Clenshaw-Curtis), which allows exact result using only one more grid-point than the classical Gauss-Legendre quadrature. This allows SHTns to efficiently use the DCT optimization, but also to use regular grids with almost half the grid points as usual.
The theoretical result is that for a function band-limited by L, L+2 equispaced grid-points allow us to fully recover the spectral content. There is, however, a drawback for non-linear terms : for a product of two functions band-limited to L, we would require L*2+2 grid points, whereas the Gauss-Legendre quadrature would only require (L+1)*3/2 grid-points if we are interested in only the first L modes of the product.
There is a slight loss of accuracy due to round-off errors (as an example, relative errors with DCT are around 1.e-11 instead of 1.e-12 without for lmax around 500). If you can live with it (you really should), the DCT-based algorithm performs much faster on small m's : twice to four times faster for axisymmetric transforms, and between 1.5 and 1.2 times faster on non-axisymmetric ones. For large m's however, the spatial-domain polar optimization takes the lead.
Note also that the DCT algorithm, while being usually faster, requires significantly larger initialization time. It is then suitable for performing many transforms (as in a direct numerical simulations).
Runtime tuning of algorithm
The default mode used by SHTns is to measure performance of the different algorithms, and choose the one that performs best (it will also check that the accuracy is good enough). However, there are situation where either the Gauss-Legendre algorithm or a regular grid is required, and you can choose to do so using the adequate shtns_type when calling shtns_init or shtns_set_grid.
